Since exactly the same analyzer is also used on-line, knowledge of the analyzer can be very useful during experiments.
The analyzer consists of two parts: a system part which is responsible
for reading/writing events in various formats and a user part which
actually does the experiment specific data analysis.
Multi stage concept
In order to make data analysis more flexible, a multi-stage concept
has been chosen for the analyzer. A raw event is passed through several
stages in the analyzer, where each stage has a specific task. The stages
read part of the event, analyze it and can add the results of the
analysis back to the event. Therefore, each stage in the chain can
read all results from previous stages.
The first stages in the chain typically deal with data calibration, while the last stages contain the "physics" code, which produces physical results. The multi stage concept allows the collaboration to use standard modules for the calibration stages which ensures that all members deal with the identical calibrated data, while the last stages can be modified by individuals to look at different aspects of the data.
This concept is somehow different of the usage of DST's (data summary tapes) in other experiments. Instead of producing some intermediate data which gets distributed, all analysis is performed always on the original raw data. The advantage of this concept is that one still has access to the first analysis stages (like the calibration) when the data analysis has progressed far. If one is in doubt about the calibration, one can always go back and test a different calibration method which is not possible if one works on pre-calibrated DST data.
Data banks
To reflect the multi-stage concept in the data structures, a bank
system is used for event storage. A bank is a sub-part of an event. It
can be of variable length (like sparcified ADC data) or of fixed
length. A fixed bank can event contain different data types like
integers and floating point values, while a variable length bank
can only contain one data type.
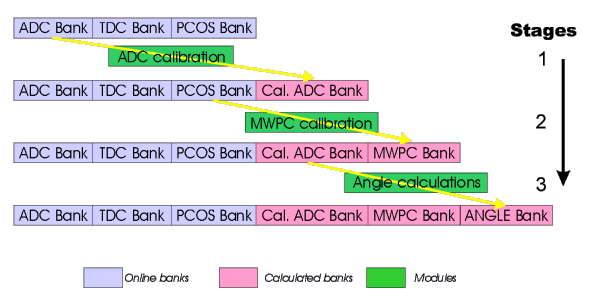
The online system produces banks for different parts of the detector, like a ADC bank, a TDC bank, a scaler bank and so on. The first stages in the analyzer will use these banks to produce calibrated data like energy deposition in MeV in an "calibrated ADC" bank, track position in mm in a "MWPC" bank and so on. User's can at the end add private banks which contains variables they are interested in.
Since the contents of banks is defined in a database, the system part of the analyzer knows how to interprete the contents of an event. This way, N-tuples can be booked automatically by the system. When running off-line, column-wise N-tuples are used. Each bank is booked as a "block" (HBOOK manual, p. 23) in an CWN-tuple. The ID of the CWNT is the same as the event id.
Following picture gives an overview of a typical set-up:
Several modules use banks from the online system to produce new, calculated banks. At the end of an analysis process, events are written to disk. Each bank has a flag telling the system if this bank should be included in the output file. By supressing online banks, the amount of data in the output file can be reduced significantly.
Modules
The analysis at each stage of the analyzer is performed by a module.
Each module lives in a different source file and exports routines
which are called at each event and at the beginning and end of a run.
Currently (May 97), modules have to be written in the C-language.
Each module can use a set of parameters, which are stored in the
online database (see next paragraph). This has the advantage that
the parameters can be changed without recompilation of the analyzer.
Modules can be classified into two classes: Standard modules and private modules. Standard modules are generally accepted by all collaboration members and used in every analysis. Initially, there are standard modules for all kinds of calibration. If standard modules are used by everybody, one is ensured that one deals with identical calibrated data. User modules are written by individuals to look into specific aspects of the data, like to do the real "physics" analysis. Over time, user modules which are generally accepted by the collaboration can be used as standard modules. If a specific method is established during offline analysis, it can go straight to the online analysis of the next beam time, so one gets already online the same results as in the last offline analysis.
Online database
The online database (ODB) stores all variables which concern a
specific experiment. It is used online and offline. It resides
completely in shared memory to allow fast access to the data
stored (~50.000 accesses per second). The ODB is structured
hierarchically like a file system. Files are called keys and
file contents are simply called data. Keys can reside in directories
which themselves can be subdirectories. A full key name is
therefore described by the full directory path like
"/analyzer/parameters/global/ADC threshold" = 12.5Each key can contain a single value of any type (integer, real, string, etc) or an array of values of the same type. To view and change values in the ODB, a general purpose editor called ODBEdit has been written. The most important ODBEdit commands are "cd
Following subdirectories are important when running an analyzer:
/Equipment/[name]/Variables Contains the event definition
of a specific event. [name]
can be "trigger", "scaler", "hv"
and so on.
/Runinfo Contains information about the
current run.
/Analyzer/Module Switches Enable switches for all
modules. A "0" switches a
module off during analysis.
/Analyzer/Parameters Contains parameters for all
analyzer modules.
/Analyzer/Bank Switches Output flags for all banks. A
"1" indicates that the given
bank should be included in
the analyzer output.
/Analyzer/Output Info about the analyzer output.
Entries in the ODB can be changed in two ways. First directly
by using ODBEdit. This will be mostly done when running online.
During data taking, parameters can be changed and the effect of
the change can be inspected immediately by looking at N-tuples
and histos. The second way is by configuration files. Subtrees
of the ODB can be saved and loaded in a simple ASCII format. When
running the analyzer offline, configuration files can be loaded
with the -c flag. This way, different configuration parameters can
be loaded for individual runs. The configuration files have an
.odb extension.
Data formats
The analyzer can read data from files, tapes or the online DAQ
system. It can write events or specific banks inside events to
output files.
The analyzer supports currently three different file formats: MIDAS binary (.mid), pure ASCII files (.asc) and HBOOK rz files (.rz) with column-wise N-tupels and row-wise N-tuples. While the rz file format can only be used for the analyzer output, .mid and .asc files can also be read by the analyzer. Additionally, these files can be written and read directly in GNU-zipped format (.asc.gz and .mid.gz). The data is compressed and decompressed on-the-fly. While this method saves about 50% of disk space, it takes about 20% more CPU time to decompress .gz files.
Inforation about the installation of the analyzer can be obtained in a seperate document.

S. Ritt, 2 May 1997